PyTorch 实现和 ImageBind 的预训练模型。有关详细信息,请参阅论文:图像绑定:一个嵌入空间来绑定所有内容。
ImageBind 学习跨六种不同模式的联合嵌入 – 图像、文本、音频、深度、热量和 IMU 数据。它支持“开箱即用”的新型紧急应用,包括跨模态检索、使用算术组合模态、跨模态检测和生成。
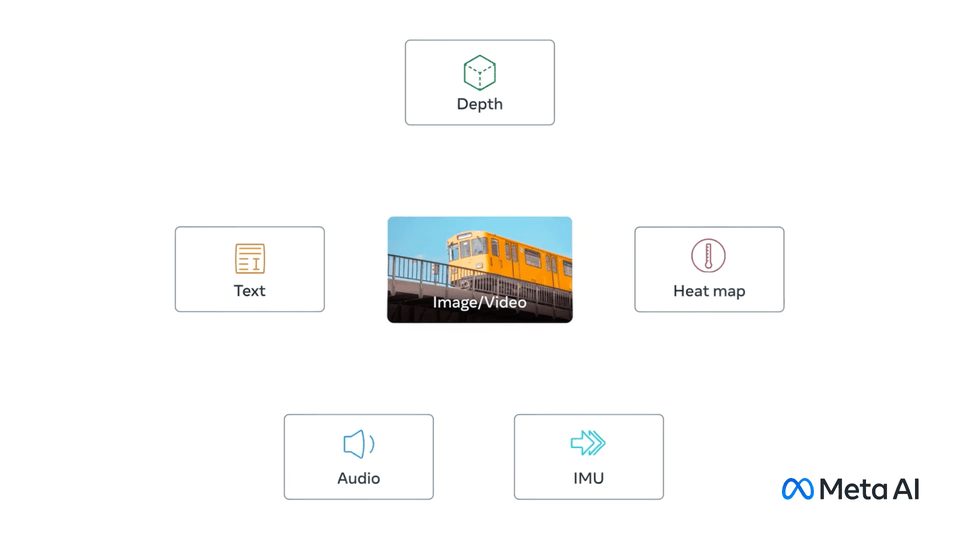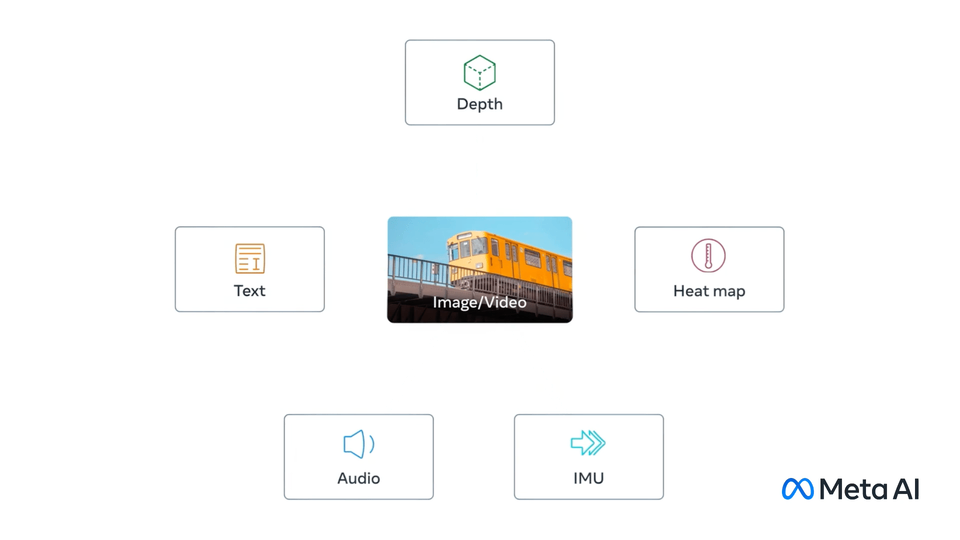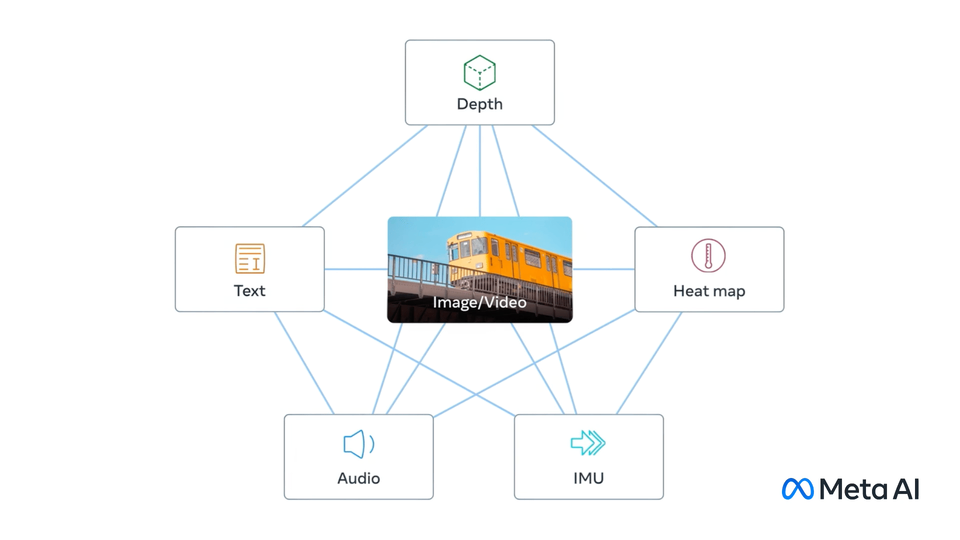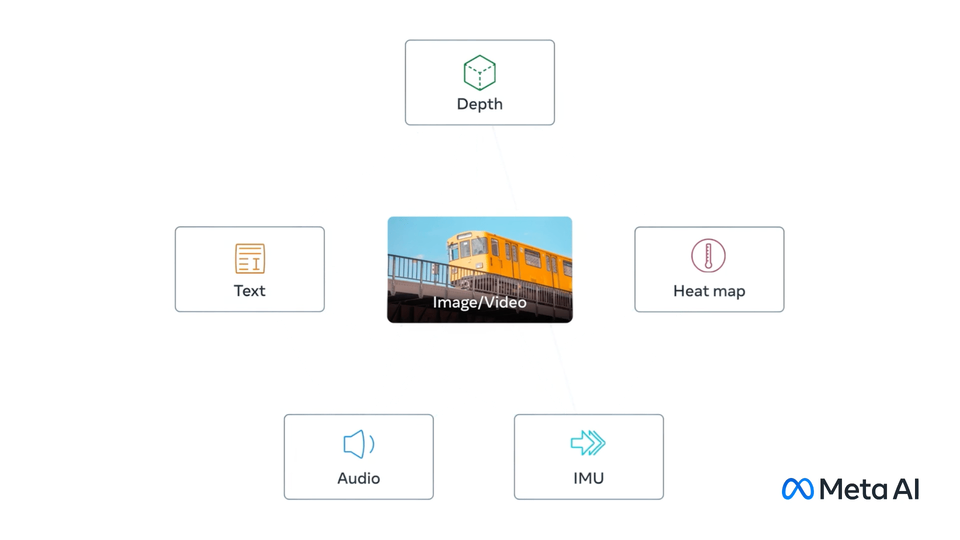
图像绑定模型
新兴的零镜头分类性能。
| 型 | IN1k | K400 | 纽约大学-D | 电调 | 利维普 | 自我4D | 下载 |
|---|---|---|---|---|---|---|---|
| imagebind_huge | 77.7 | 50.0 | 54.0 | 66.9 | 63.4 | 25.0 | 检查站 |
用法
安装 pytorch 1.13+ 和其他第三方依赖项。
conda create --name imagebind python=3.8 -y
conda activate imagebind
pip install -r requirements.txt
对于 Windows 用户,您可能需要安装才能读取/写入音频文件。(谢谢@congyue1977)soundfile
pip install soundfile
提取和比较各种模式(例如图像、文本和音频)的特征。
import data
import torch
from models import imagebind_model
from models.imagebind_model import ModalityType
text_list=["A dog.", "A car", "A bird"]
image_paths=[".assets/dog_image.jpg", ".assets/car_image.jpg", ".assets/bird_image.jpg"]
audio_paths=[".assets/dog_audio.wav", ".assets/car_audio.wav", ".assets/bird_audio.wav"]
device = "cuda:0" if torch.cuda.is_available() else "cpu"
# Instantiate model
model = imagebind_model.imagebind_huge(pretrained=True)
model.eval()
model.to(device)
# Load data
inputs = {
ModalityType.TEXT: data.load_and_transform_text(text_list, device),
ModalityType.VISION: data.load_and_transform_vision_data(image_paths, device),
ModalityType.AUDIO: data.load_and_transform_audio_data(audio_paths, device),
}
with torch.no_grad():
embeddings = model(inputs)
print(
"Vision x Text: ",
torch.softmax(embeddings[ModalityType.VISION] @ embeddings[ModalityType.TEXT].T, dim=-1),
)
print(
"Audio x Text: ",
torch.softmax(embeddings[ModalityType.AUDIO] @ embeddings[ModalityType.TEXT].T, dim=-1),
)
print(
"Vision x Audio: ",
torch.softmax(embeddings[ModalityType.VISION] @ embeddings[ModalityType.AUDIO].T, dim=-1),
)
# Expected output:
#
# Vision x Text:
# tensor([[9.9761e-01, 2.3694e-03, 1.8612e-05],
# [3.3836e-05, 9.9994e-01, 2.4118e-05],
# [4.7997e-05, 1.3496e-02, 9.8646e-01]])
#
# Audio x Text:
# tensor([[1., 0., 0.],
# [0., 1., 0.],
# [0., 0., 1.]])
#
# Vision x Audio:
# tensor([[0.8070, 0.1088, 0.0842],
# [0.1036, 0.7884, 0.1079],
# [0.0018, 0.0022, 0.9960]])
© 版权声明
文章版权归作者所有,未经允许请勿转载。